Building a Retrieval-Augmented QA Chatbot
Building a QA chatbot with memory using Langchain, Faiss, Streamlit and OpenAI (Retrieval-Augmented Generation (RAG)).

Data Engineer | BI & Analytics
Building scalable data pipelines and analytics platforms that turn data into decisions.
I’m Jeevaharan, a data professional with 4 years of experience building scalable data platforms and analytics solutions across industrial, supply chain, financial services, and healthcare domains. My work focuses on data engineering and cloud-based systems, where I’ve designed high-performance data pipelines, orchestrated complex workflows, and supported large-scale migrations from on-premises systems to cloud platforms such as AWS, Azure and Snowflake.
I’ve also worked on generative AI and LLM-based proof of concepts, building chatbot and AI-driven solutions that integrate with enterprise data systems. I hold a Master’s degree in Data Science from the University at Buffalo (SUNY), with a strong foundation in statistical data mining, machine learning, and data-intensive computing.
I enjoy building reliable, maintainable data systems and collaborating with teams to solve real-world problems at scale.



Aug 2024 - Dec 2025 | CGPA - 4.0/4.0
Coursework: Data Intensive Computing, Statistical Data Mining, Machine Learning, Probability and Data Analysis.
Aug 2017 - June 2021 | CGPA - 8.89/10
Coursework: Problem Solving and Python Programming, Microprocessors and Microcontrollers, Introduction to C Programming, Object Oriented Programming.
Recognized for successfully designing and implementing robust and performance-optimized ETL pipelines, supporting critical business reports and decisions.
Recognized for outstanding team collaboration and successful migration from Cloudera Hadoop to an AWS-based Snowflake solution, delivering significant cost savings.
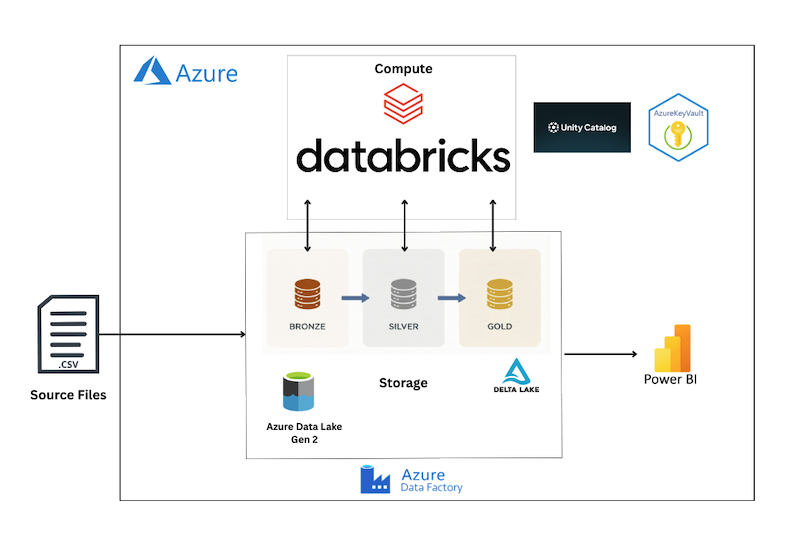
End-to-end analytics platform built on Azure Databricks using the Medallion Architecture.
GenAI-powered job assistant using Retrieval-Augmented Generation (RAG) to match profiles with suitable roles.
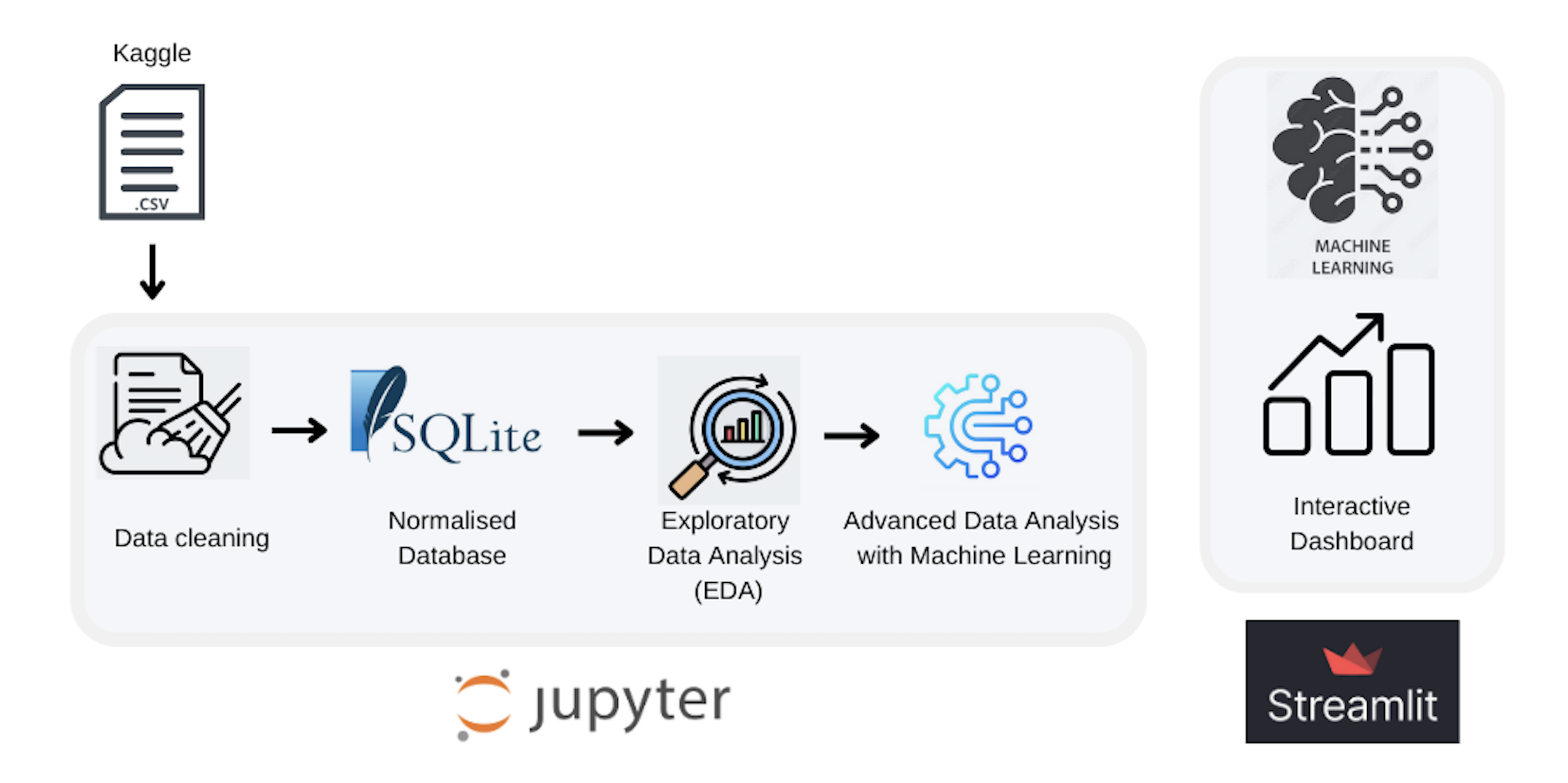
Applied machine learning and statistical analysis to predict heart attack risk from clinical data.
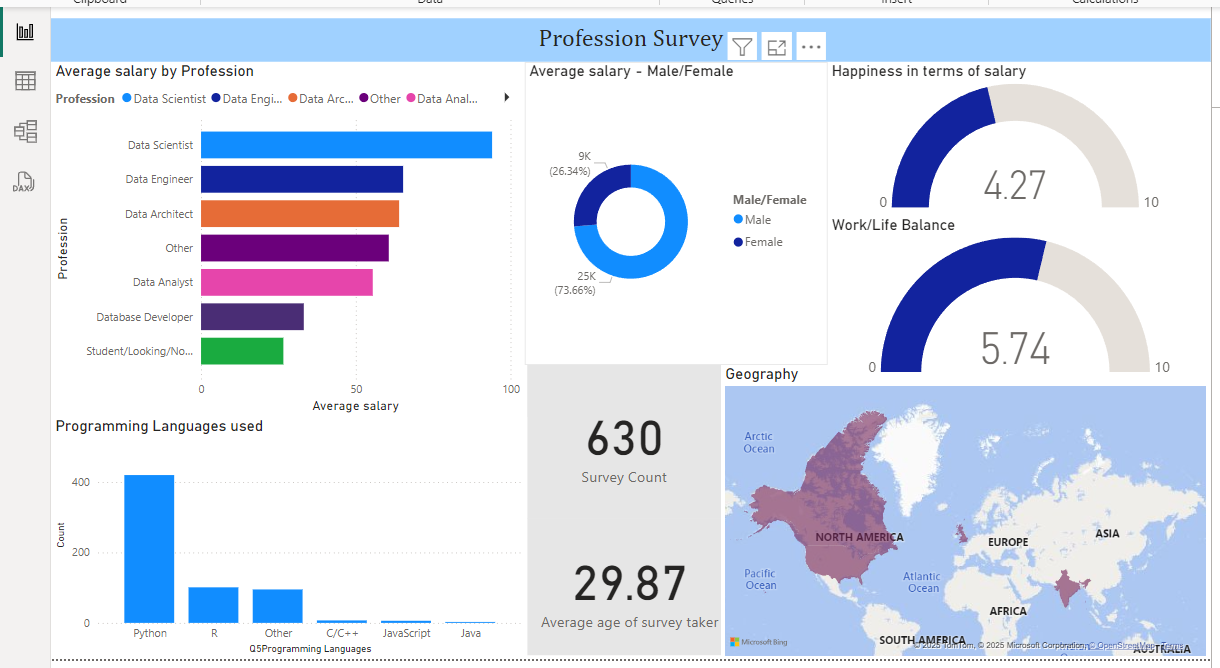
Interactive Power BI dashboard analyzing salaries, skills, demographics, and job satisfaction among data professionals.